
티스토리 뷰
아래 링크의 [알리바바 클라우드 기계학습 - 인공지능을 손끝에 : 2. 주요 기술 특징]에 이어서 [3. 전형 사례]를 번역한다.
http://multeng.tistory.com/15
알리바바 클라우드 기계학습 - 인공지능을 손끝에 가능하게 하다 - (3)
3.전형 사례
3.1 알리바바 그룹 내부 사례
알리바바 내부의 3개 애플리케이션 시나리오를 아래에서 설명한다.
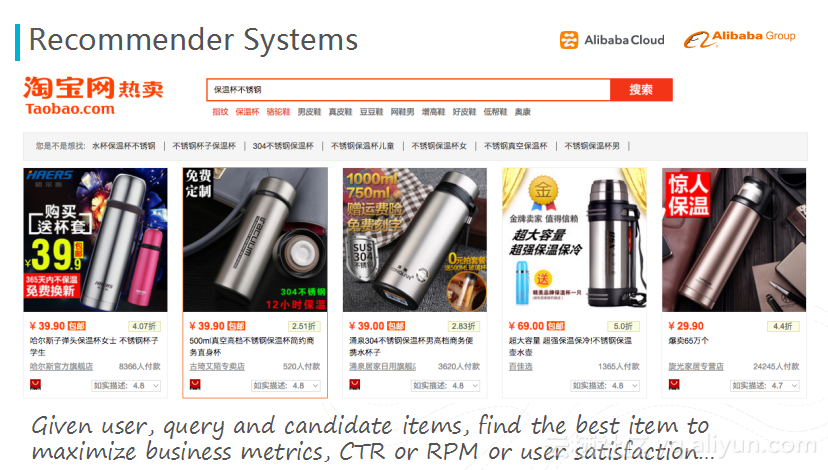
애플리케이션 1 : 추천 계통
첫번째 애플리케이션은 추천 계통이며, 주로 파라미터 서버를 추천 계통 내에서 응용한다. 타오빠오에서 쇼핑할 때, 검색으로 표시되는 상품은 일반적으로 모두 매우 맞춤화된 추천이며, 이는 상품 정보 및 사용자 개인 정보와 행동 정보인 3가지 특징에 근거하여 취득한다. 해당 프로세스 중에 형성된 특징은 일반적으로 모두 매우 크고, 파라미터 서버에는 없을 때, 채택하는 것은 MPI 구현 방법이며, MPI 중 모든 모델은 한 개의 노드에 존재하나 자체 물리적 메모리 한계로 제한되어 있으며, 2000만 개의 특징 밖에 처리하지 못한다; 파라미터 서버를 사용하여, 우리들은 더 큰 모델을 ( 예를 들면, 백억 개 특징의 모델) 수십 개, 심지어 수백 개의 파라미터 서버에 분산하여, 규모의 병목을 해소하고, 모델 성능의 향상을 실현한다.
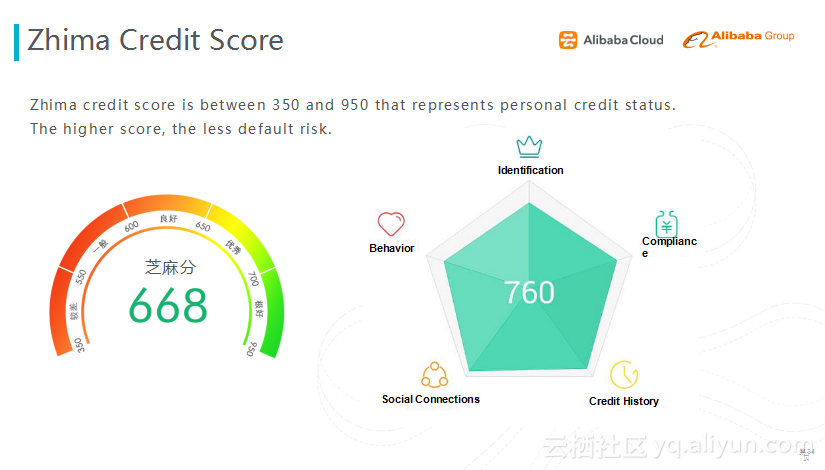
애플리케이션 2 : 지마(芝麻) 신용 점수
두번째 애플리케이션은 지마 신용 점수이다. 지마 신용 점수는 개인 데이터로 개인 신용을 평가해 왔다. 지마 신용 점수를 매길 때, 우리들은 개인 정보를 5대 차원으로 나누었다 : 신분 특질, 약속 이행 능력, 신용 이력, SNS 친구들 상황 및 개인 행동으로 신용 등급을 평가한다.
작년에 우리들은 DNN 딥러닝 모델을 이용하여, 지마 신용 점수 평가 모델을 만들어 보았다. 입력은 사용자 원래 특징, 전문가 지식에 기반하여 수천 차원의 특징을 5개 부분으로 나누었으며, 각 부분은 평가 차원에 대응한다. 우리들은 1개의 현지 구조화된 딥러닝 학습 네트워크를 통하여 관련 영역의 평점을 포착해 왔다. 업무는 해석을 필요하기 때문에, 우리들은 모델의 구조를 변경하여, 최상단의 은닉층에 총 5개의 뉴론이 있으며, 각 뉴론의 출력은 모두 5개 차원의 값 변화에 대응하고 있다 ; 한 층 아래는 변경된 차원 점수의 인자층이다 ; 이러한 현지 구조 방식으로 모델의 해석 가능성을 유지한다.
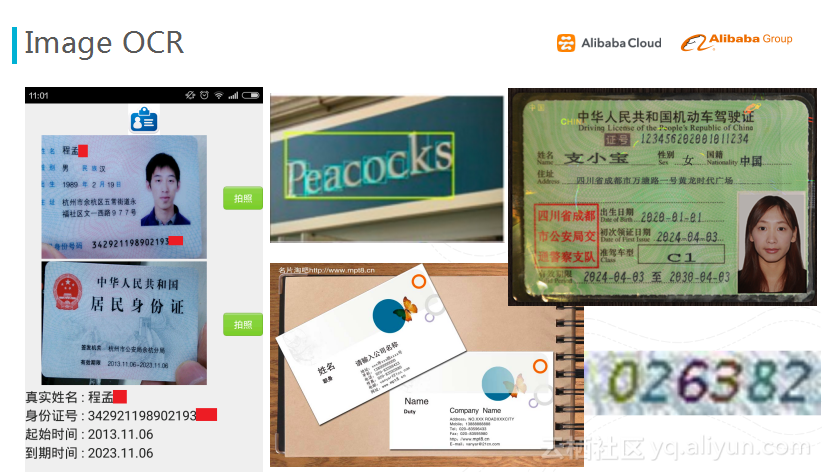
애플리케이션 3 : 광학 문자 인식
마지막 애플리케이션은 이미지의 광학 문자 인식(OCR)이다. 우리들은 템플릿 유형, 증명서 유형의 문자 인식, 그리고 자연 환경에서의 문자 인식을 주로 강화한다. 탬플릿 서비스 (신분증 인식) 를 슈쟈(数加) 플랫폼에서 강화함으로써 관련 입구를 제공하며, 신분증 단어 인식률은 현재 96.6% 이상에 도달할 수 있으며, 전체 인식률은 93%이다. 인식에 사용되는 것은 CNN 모델, 그러나 실제로 전체 과정은 길어서, 모델링 한 개를 딥러닝한다고 해결할 수 있는 문제가 아니며, 레이아웃 분석, 문자 행의 측정, 분할 등등의 기술을 포함한다. CNN 훈련에도 우리들은 다중 기기, 다중 카드 분산 알고리듬 제품을 채택하며, 이전에도 1천만개의 이미지 훈련 CNN 모델을 이용하여, 대략 70시간을 소모했으며, 반복 속도는 매우 느렸다 ; 분산식 8 카드 제품을 채택 후, 10시간이 걸리지 않아서 모델 훈련이 완성될 수 있다. 현행 OCR의 서비스는 이미 인기 있는 알리바바 클라우드 시장의 API가 되었으며, 더욱이 증명서 유형의 인식, 정확도가 높아졌으며, 모든 종류를 갖추었으며, 업무 시나리오에서 광범위하게 사용될 수 있는 데이터 서비스의 일종이 되었다.
3.2 외부 업무 사례
대외 서비스 방면에서 알리바바 클라우드 기계학습 플랫폼은 이미 금융, 부동산, 교육, 의료, 날씨 등 직종에서 효과를 발휘하고 있다 —— 그 중 상대적으로 전형적인 사례는 밍유안(明源) 클라우드를 부동산 산업에 응용하는 것이며, 밍유안 자회사의 클라우드 차이코우(采购) 플랫폼은 알리바바 클라우드 기계학습 플랫폼으로 판매 CRM 계통들을 편성했으며, 해당 계통은 데이터의 예비처리, 특징 엔지니어링, 기계학습, 평가, 예측 및 조율을 포함한다. 알리바바 클라우드 기계학습 플랫폼은 밍유안이 잠재 사용자의 위치를 정확히 찾도록 도와주며, 해당 판매 점유률을 100%에 근접하게 향상시킨다. 작년 11월, 알리바바 클라우드가 CBS 회의에서 발표한 《Nonlinear Machine Learning Approach by Cloud Computing to Short-Term Precipitation Forecasting》 보고서는, 광동성 기상국이 제공한 대규모 기상 관측 데이터와 결합하여, 우리들은 알리바바 클라우드 기계학습 플랫폼으로 근접 예보(0~3시간 내)의 강우량에 대한 예측을 모델링 하였다. 데이터 청소, 특징 엔지니어링, 또는 비선형 기계학습 알고리듬 훈련과 결과 평과를 막론하고, 모두가 대규모 시각화 기계학습 플랫폼 PAI 개발이 완성되었기 때문이다. 최대 장점은 사용자가 많은 기반 인프라 알고리듬 지식을 파악할 필요가 없다는 것이고, 어떤한 프로그래밍도 필요 없고, PAI에서 기존의 컴포넌트를 드래그하기만 하면 즉시 원클릭으로 프로그램 샐행이 되며, 이번의 광동성 기상 강수 예측의 예시로써 모델링 프로세스가 아래의 도면에 표시되어 있다.
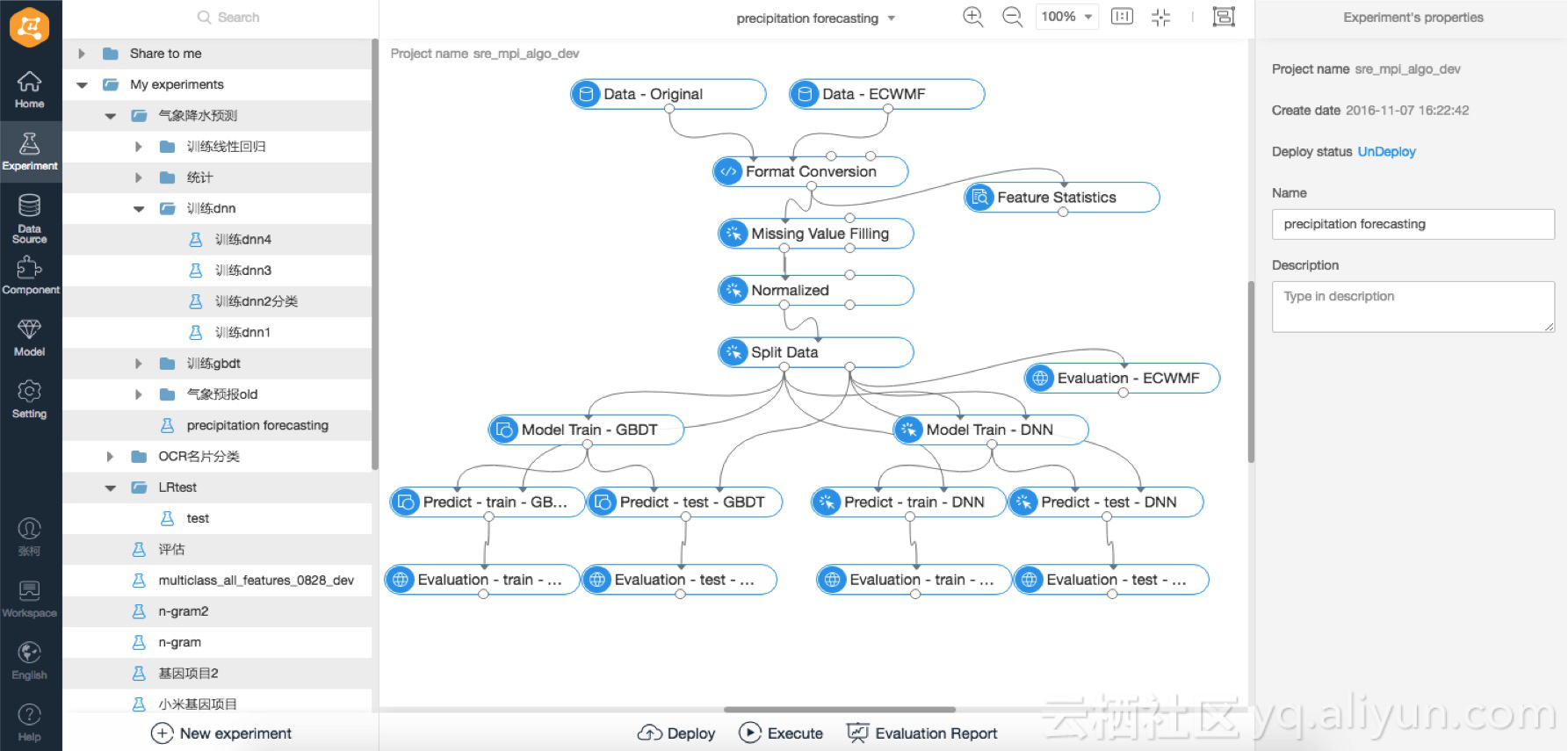
PAI 모델링 이용 효과는 이미 업계에서 상용되는 방법보다 우수하며, 기계학습을 기상 영역에서 어느 정도 다시 증명하였으며, 특히 강우량에 근접하는 장점이 증명되었다. 앞으로도 우리들은 위성 구름 사진, 레이더 에코 등 더 많은 기상 관련 데이터를 아리바바 클라우드에 계속 입력해 볼 것이며, 시간 차원에서 더 긴 이력 데이터를 입력하여 대량 데이터의 효과를 충분히 발휘할 수 있다. 동시에 혁신적 방법으로는 우리들은 더 많은 모델을 입력하여 연구 작업할 수 있으며, 예를 들면 많은 사이트의 LSTM 모델링, 시간 차원에서의 가우스 프로세스 모델링 등등이 있다. 기상 예보의 대중 혁신을 고무하기 위해, 데이터, 알고리듬, 또는 애플리케이션을 막론하고, 알리바바 클라우드는 앞으로 기상 app store를 만들 것이며, 모두가 온라인으로 기여하기 편하게 할 것이며, 흥미로운 애플리케이션을 배포 및 검색할 것이다.
알리바바 클라우드 기계학습 플랫폼은 인공지능의 매체 및 원동력으로써, 점차 각종 직업의 생산 방식에 파고 들고 있다.
'기계학습' 카테고리의 다른 글
| 알리바바 클라우드 HPC와 컨테이너 서비스에서 반 고흐 같은 작화 (0) | 2017.06.06 |
|---|---|
| 알리바바 클라우드 기계학습 - 인공지능을 손끝에 : 2. 주요 기술 특징 (0) | 2017.06.04 |
| 알리바바 클라우드 기계학습 - 인공지능을 손끝에 : 1. 서론 (0) | 2017.06.03 |
- Total
- Today
- Yesterday
- 영어번역
- 원서접수
- 실업인정일
- 클라우드
- 불어번역
- 영한번역
- 구직급여 받는법
- 실업급여 받는법
- 독일어번역
- 서반어
- 불어 번역
- 알리바바
- 북녘말
- 취업희망카드
- 실업급여
- 정보처리기사
- 패러디
- 일어
- 실업인정 신청서
- 중국어번역
- 독어번역
- 둘리
- 인공지능
- 기계학습
- 포르투갈어 번역
- 독어
- 번역공증
- 실업급여 수급자
- 독일어
- 딥러닝
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |